

Most AI sales coaching tools are solving for the wrong outcome. They optimize for visibility into what happened on calls, when the actual problem is that reps keep doing the same thing on the next call anyway.
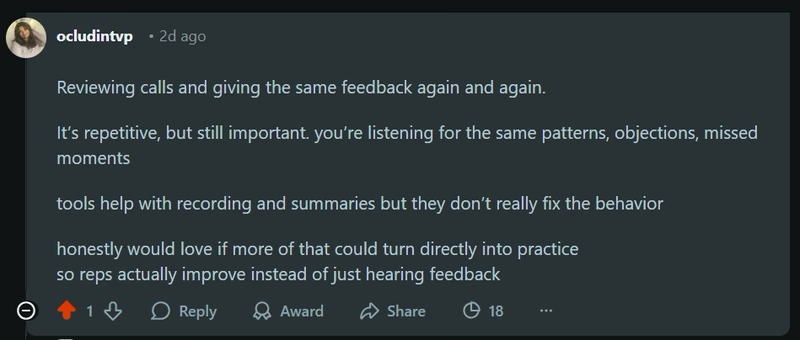
The market has flooded with platforms claiming to solve the entire coaching problem. Conversation intelligence tools analyze calls. LMS platforms deliver training modules. CRM dashboards track pipeline metrics. Each does its piece. Each leaves the same gap: the one between seeing a problem clearly and systematically changing the behavior driving it. Teams running 75+ B2B sales calls per day, like Tensar CMC, can drift through multiple quarters of sales decline without anyone catching it, because the tools existed and the feedback loop did not.
For L&D leaders and sales enablement teams evaluating these tools, the right question is not "which tool is best?" It is "where do these tools structurally fall short, and what does a complete coaching system actually require?" According to CSO Insights, organizations with a formal coaching process see 91.2% of reps achieving quota, compared to 84.7% without one. That 6.5-point gap is not closed by adding another point solution to your stack. It is closed by connecting practice to live performance in a single, continuous workflow. Most AI coaching tools never get there.
Understanding the Limitations of Traditional AI Sales Coaching Tools
Visibility is not coaching. Coaching is not behavior change. Most AI coaching tools were built to give managers visibility into what reps say on calls, and that is where they stop.
The limitations are not failures of engineering. They are design choices. A tool built around call recording will naturally be weak at pre-call preparation. A tool designed for content management will not score objection handling. Understanding these boundaries helps enablement leaders build smarter stacks and avoid the expensive mistake of expecting one platform to do everything.
These design choices map predictably to tool categories. Conversation intelligence platforms (Gong, Chorus, Avoma) are strong on call analysis but weak at connecting that analysis to structured practice. Sales enablement platforms (SalesHood, Highspot, Seismic) are strong on content delivery and learning management but tend to be weak on behavioral scoring tied to live performance. Revenue forecasting tools (Clari) surface pipeline risk but do not coach the rep behaviors that created that risk. Each category has a ceiling, and that ceiling becomes visible at the same point: when your team can see the problem clearly but cannot systematically change the behavior driving it.
The Need for Human Connection
AI can tell you a rep's talk-to-listen ratio was 72%. It can flag that a competitor was mentioned at the 14-minute mark. It cannot read the emotional temperature of a conversation, recognize when a buyer's silence means confusion versus interest, or coach a rep through the anxiety of asking for a six-figure commitment.
Here is the nuance most vendors skip over: AI coaching accelerates skill development for diagnosable, repeatable gaps such as discovery question sequencing, objection handling technique, or value message delivery. It does not fix a broken incentive structure, a manager who does not coach, or a deal environment that requires political navigation across a 10-person buying committee. Harris Consulting Group's research on complex B2B sales identifies exactly this pattern: deals involving 10 or more stakeholders require relational and navigational judgment that no scoring algorithm was designed to assess. Buying committees now average 11 stakeholders. That means the demands on reps have grown well past what single-call scoring tools were built to address.
Most AI coaching tools generate feedback after the conversation is over. They score what happened. They do not help reps build the situational awareness needed to adjust in the moment. That is a structural limitation, not a configuration problem.
A Harvard Business Review study found that companies using a hybrid coaching model, combining AI analysis with human coaching, deliver stronger results than either approach alone. Organizations that treat the AI tool as a substitute for manager coaching instead of a force multiplier struggle most.
The risk for organizations: teams that over-rely on AI feedback start optimizing for metrics the tool can measure (talk time, question count, keyword usage) rather than the outcomes that actually close deals (trust, timing, relevance). Reps learn to game the scorecard instead of reading the room.
In practice, this pattern appears in almost every organization that arrives with a mature conversation intelligence stack but stagnating win rates. The dashboard shows strong activity metrics and healthy talk-track adherence. The pipeline tells a different story: close rates are flat, deal cycles are lengthening, and the reps who score highest on call scorecards are not necessarily the ones closing the most business.
The disconnect is predictable. Tools like Gong and Chorus do live call review well, but they stop at the call itself. They do not integrate with AI simulations or structured improvement workflows. The analysis happens; the behavior stays the same.
Complex Negotiation Skills
Multi-threaded enterprise deals are where most AI coaching tools hit a hard ceiling. A typical B2B buying committee includes 6 to 10 decision-makers, according to Gartner. Each stakeholder has different priorities, different objection patterns, and different definitions of value.
AI tools trained on generalized call data struggle with this complexity. They can identify that a rep discussed pricing. They cannot evaluate whether the pricing conversation happened with the right stakeholder at the right stage. They can flag a missed objection but cannot assess whether the rep intentionally deferred that objection to build a coalition with a champion first.
Negotiation at the enterprise level is sequential, political, and deeply contextual. Most AI scoring models treat each call as an isolated event. They do not connect the thread across a six-month sales cycle where the real skill is not what you say on any single call but how you orchestrate the sequence of conversations across an entire buying committee.
James Spencer at CMC Tensar, a Fortune 500 industrial company, described the practical version of this problem: "I don't know what anybody is saying on the phone at all, and have no analytics or visibility into that, and since we're launching a new process, people are gonna be not good at it right, and I don't mean it like in a judgmental way, we're launching something new and I want to train people on the right things." CMC Tensar has a team of 10 inside sales reps and 50 outside reps. Without a system that connects call behavior to coaching, the launch of an entirely new BDR-like sales process is essentially flying blind.
This creates a blind spot for enablement teams: the reps who look strong on per-call metrics may actually be losing complex deals because they are optimizing each conversation independently rather than managing the overall deal strategy. For teams in financial services or regulated industries where multi-stakeholder deals are the norm, this gap between per-call scoring and deal-level coaching is where quota attainment is won or lost.
A practical test for your team: Pull your top five reps by per-call AI scores and compare them to your top five by win rate on deals with three or more stakeholders. If those are not the same five people, your coaching tool is measuring the wrong thing.
Tailored Coaching Experiences
Generic roleplay scenarios are the training equivalent of reading a textbook about swimming. You understand the theory. You still cannot swim.
A study by Training Industry found that 74% of sales reps say generic training does not reflect their actual selling environment. The objections are wrong. The competitive landscape is off. The buyer persona sounds like a template, not a real person. James Spencer at CMC Tensar put it plainly: "The folks who were hired to be the inside sales folks are really good at being engineers, but they're baby salespeople, so that's what I need to help them with." Generic discovery call scripts built for experienced AEs are exactly the wrong tool for technical hires learning to sell for the first time. The context mismatch is the difference between practice that accelerates development and practice that gets abandoned within weeks.
Most AI coaching platforms ship with pre-built scenarios or allow basic customization through prompt templates. The result is practice that feels artificial. Reps go through the motions, check the box, and return to selling the way they always have.
The deeper problem is feedback calibration. When a tool uses the same scoring rubric across all scenarios, it cannot account for the difference between an SDR's discovery call and an enterprise AE's executive briefing. A question that is effective in one context is a wasted breath in another. Without scenario-specific scoring, the feedback a rep receives may be technically correct but strategically irrelevant.
This is where adoption breaks down. Not because the tool is hard to use, but because reps stop trusting the feedback. Once trust is gone, the platform becomes shelfware.
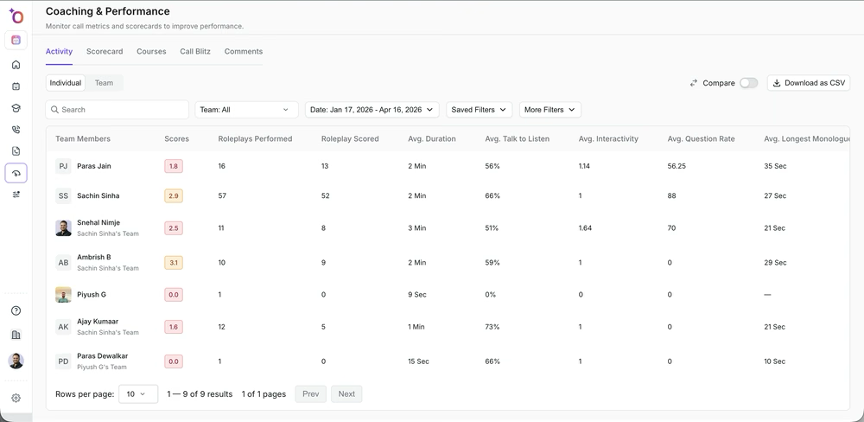
The AI Coaching Maturity Model: Where Does Your Organization Actually Stand?
Most organizations overestimate their position on the coaching maturity curve. Use the model below to locate your team honestly, then read the transitions between levels as a checklist for what to build next.
Level 1: Ad Hoc Coaching
Coaching happens informally, driven by individual manager initiative. No consistent methodology. No measurement. Feedback is verbal and forgotten within days. AI tools at this level are usually purchased but underused.
How to tell you're here: If coaching quality depends entirely on which manager a rep reports to, you are at Level 1.
Level 2: Reactive Analysis
The organization records calls and reviews some of them. Conversation intelligence tools provide post-call insights. Managers cherry-pick calls to review. Coaching is backward-looking and inconsistent across teams.
How to tell you're here: You have a conversation intelligence tool and a handful of managers use it regularly, but there is no standard for which calls get reviewed or what happens after a coaching session.
Level 3: Structured Practice
Reps practice against scenarios before real conversations. Scoring rubrics exist but may not connect to live call evaluation. Managers can identify skill gaps but lack evidence of whether practice translates to performance. This is where most well-run enablement programs plateau.
How to tell you're here: You run roleplays or certifications, but if someone asked "did last month's objection handling training actually change call outcomes?" you could not answer with data.
Level 4: Connected Feedback
Practice scores and live call scores use the same framework. Managers can compare what a rep does in roleplay with what they do on actual calls. Gaps between practice and execution become visible and coachable. Few organizations reach this level because it requires a unified scoring system across both environments.
How to tell you're here: You can pull up a rep's practice score on discovery alongside their live call discovery score and see the gap in the same dashboard.
Level 5: Closed-Loop Coaching
Insights from live calls automatically generate targeted practice. Coaching is continuous, personalized, and evidence-based. Improvement is measurable over time. The system self-corrects: as reps improve, their practice adapts. At this level, coaching is an operating system, not an initiative.
How to tell you're here: When a rep struggles with competitive positioning on a Thursday call, a targeted practice scenario on that exact gap appears in their queue by Friday morning, scored against the same rubric.
Most AI coaching tools are designed to serve Level 2 or Level 3 organizations. They help you see what happened. They do not close the loop between seeing and changing. Conversation intelligence platforms generally enable Level 2. Sales enablement and LMS platforms generally enable Level 3. Revenue forecasting tools do not directly address coaching maturity at any level. Platforms built around closed-loop coaching, where practice and live call analysis share a scoring framework and each informs the other, are the only category designed to reach Levels 4 and 5.
Credit unions and financial services teams illustrate this gap clearly. They often run structured in-person training programs with skilled coaches, but the coaching is geographically dispersed, the feedback is inconsistent across branches, and there is no practice layer between a training session and a live member conversation. The talent development team at Salal Credit Union identified exactly this challenge: they needed a safe, pause-able practice environment that could deliver consistent feedback across a growing branch network. That is a Level 3 need. Without the right platform, they were stuck at Level 2.
Your next step, regardless of level: Identify one skill (discovery, objection handling, or competitive positioning) and ask: "Can I see how this skill scores in practice AND on live calls, for each rep, in the same view?" If the answer is no, that is your gap and your starting point.
Key Benefits of a Closed-Loop AI Coaching Approach
The limitations outlined above are not reasons to abandon AI coaching. They are reasons to demand more from it. When AI coaching is structured as a closed loop, the benefits compound in ways that point solutions cannot replicate.
Here is what a closed-loop week looks like for a rep and a manager:
- Monday: The system flags that a rep's competitive positioning scores dropped 15 points on two live calls last week. A targeted micro-roleplay scenario focused on the specific competitor and objection pattern appears in the rep's practice queue.
- Tuesday/Wednesday: The rep completes the practice scenario. The system scores it on the same rubric used for live calls and provides immediate, specific feedback.
- Thursday: The rep runs a real call involving that competitor. The system scores the call and compares it to the practice session scores from earlier in the week.
- Friday: The manager opens their weekly coaching view and sees, for each rep, the gap between practice and live performance on the skills that matter most this quarter. Their one-on-one prep takes minutes instead of hours because the system surfaced the evidence.
That cycle is what distinguishes a closed-loop system from a stack of point solutions stitched together with manual effort.
Consistent measurement that actually means something. When the same scoring logic applies to both practice and live calls, you stop guessing whether training is working. A rep who scores 82% on objection handling in roleplay but 61% on real calls has a specific, coachable gap. That is actionable intelligence, not a dashboard metric.
Manager time that compounds. A frontline sales manager with 8 to 12 direct reports cannot manually review every call and design individualized coaching plans. A system that identifies gaps and generates targeted practice for each rep gives managers time back while increasing coaching consistency. CSO Insights reports that managers spend only 19% of their time on coaching. The right system makes that 19% far more productive. Live and Study in EU made this point directly: with 60 to 70 calls happening daily, even a weekly reporting cadence was too slow to catch performance drift before it compounds into a revenue problem. A closed-loop system does not just show managers what happened last week. It tells them what to do next.

Adoption that sticks. Reps engage with coaching when it feels relevant. Practice that mirrors real customer language and real deal context feels relevant. Generic scenarios do not. The difference in adoption rates between customized and generic roleplay is the difference between a tool that gets used and a line item that gets questioned at budget review. High-value or problematic calls can be converted into roleplays with a single action, which means the institutional knowledge embedded in your best and worst calls starts actively shaping how your team prepares.
Behavioral evidence for stakeholders. L&D leaders consistently struggle to prove training ROI. When a platform tracks skill progression from initial roleplay through certification to live call performance, you have a longitudinal view of development that finance teams and executive sponsors understand. "Rep X improved discovery question quality by 23% over 90 days, correlated with a 15% improvement in stage-2 conversion" is a fundamentally different conversation than "we delivered 40 hours of training last quarter." Teams that implement structured closed-loop coaching have seen onboarding timelines compress meaningfully, with some reducing new-rep ramp time by approximately 25% compared to manager-led coaching alone.
How a Closed-Loop System Works: AI Roleplay for Real-World Scenarios
The mechanics matter more than the theory.
Interactive Roleplay Sessions
Effective roleplay requires unpredictability. If a rep knows exactly what the AI buyer will say, they are rehearsing a script, not building a skill.
The most advanced roleplay systems use dynamic question banks and contextual reasoning to create unscripted interactions. AI personas respond to the rep's tone, intent, and specific word choices rather than following a decision tree. Multi-persona roleplays put reps in front of two or three AI stakeholders simultaneously, forcing them to navigate competing priorities in real time. Buying committees now average 11 stakeholders. Practicing with multiple AI personas in a single session builds the kind of switching ability that no single-persona tool can develop.
A live roleplay call screen showing an interactive AI-driven sales conversation in progress.
This matters most for enterprise teams preparing for QBRs, multi-stakeholder demos, or executive briefings where the ability to pivot between technical detail and business impact in a single conversation separates closers from presenters.
One question that surfaces frequently from teams evaluating this approach, as a Vestd sales leader put it, is: "Would the AI bot generate a similar scenario to better do that conversation again?" referring specifically to retention and customer success scenarios, not just new business calls. The answer is yes. Teams that build practice scenarios for renewal calls, pricing negotiations, and multi-stakeholder demos tend to see the broadest skill development across their entire revenue team.
Roleplay agents built from uploaded playbooks, product docs, and actual call recordings create practice that sounds like your buyers. CMC Tensar's James Spencer planned to load his team's custom scripts into the platform and iterate on them directly, rather than starting from a generic sales template. That is the right instinct: the closer the practice environment is to the real selling environment, the faster skills transfer.
Real-Time Feedback and Analytics
Feedback timing matters almost as much as feedback quality. Research from the Journal of Applied Psychology consistently shows that immediate feedback produces stronger learning outcomes than delayed review.
The strongest AI coaching systems provide feedback during or immediately after practice, covering multiple dimensions: discovery quality, objection handling technique, messaging accuracy, value articulation, and talk-track adherence. The real differentiator is whether that feedback connects to live performance. Tools like Gong offer strong live call review, but they are not natively designed to feed those insights into structured improvement workflows or AI simulations. A closed-loop system draws from both environments: call performance data informs what the next roleplay addresses, and roleplay scores are interpreted against the same criteria applied to real calls.
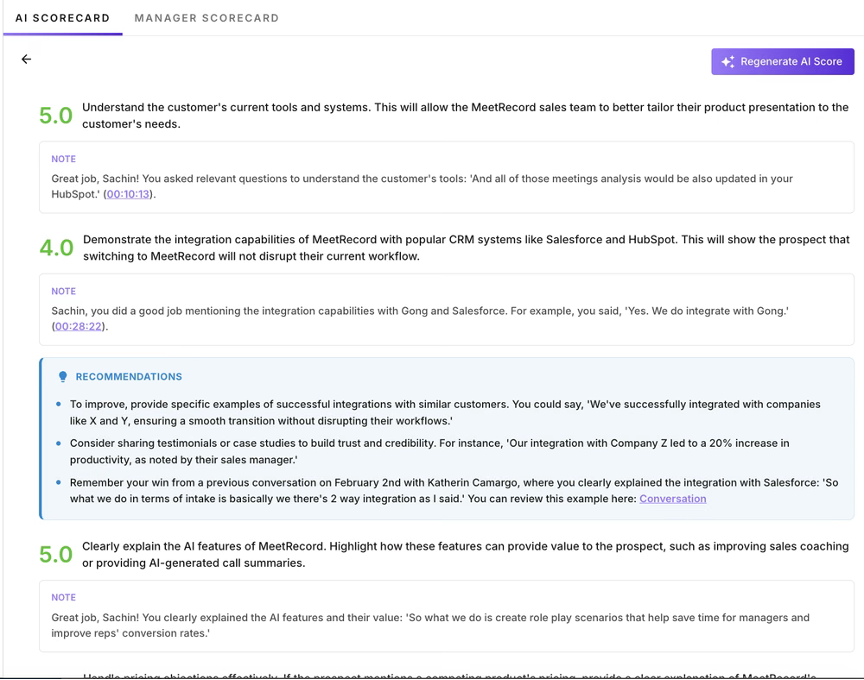
Scorecard and feedback view after a roleplay session, showing how practice is scored and connected to coaching.
When a platform scores a roleplay and then applies the same scoring framework to the rep's next real customer call, managers do not have to guess whether practice transferred. They can see the exact skills that transferred and the ones that did not. That comparison turns feedback from information into a coaching action. Instead of reviewing calls hoping to find something worth addressing, managers walk into one-on-ones with a specific gap, a specific practice session as evidence, and a specific recommendation. That is a fundamentally different coaching conversation.
Customizable Coaching Modules
One-size-fits-all coaching modules are the primary reason completion rates for sales training hover around 20% at many organizations. Generic is the enemy of adoption, and adoption is the only metric that predicts whether a coaching investment produces any return at all.
Effective customization goes beyond "choose your industry vertical." It means scorecards attached to specific reference materials, so reps see the relevant battlecard or playbook section alongside their feedback. It means the system generates micro-roleplays targeting the exact gap a rep demonstrated on their last call, not a generic refresher on discovery methodology. For regulated environments such as insurance, financial services, and healthcare, this also means attaching SOPs and process documents to agents so simulations follow required steps. Process compliance scoring confirms that required actions are actually happening, not just that the conversation sounded plausible.
This level of personalization requires deliberate setup. Enablement teams need to curate resources, configure scorecard priorities, and map scoring rubrics to specific deal stages and customer segments. It is not plug-and-play work. CMC Tensar's evaluation criteria illustrate why this setup investment matters: James Spencer's core requirement was that the platform connect with Microsoft Dynamics, map call information to specific CRM objects for CHAMP qualification, and support a custom lead scoring checklist. No out-of-the-box coaching tool supports that without configuration. But it is exactly the kind of specificity that makes coaching feel real rather than generic, because it is tied to the actual sales process the team is running. Coaching tools that add friction instead of reducing it do not last long in competitive evaluation.
Use Cases: How Different Teams Apply This Approach
Accelerating Onboarding
New reps in enterprise sales environments typically take 7 to 9 months to reach full productivity, according to the Sales Management Association. Every month of ramp time represents lost quota capacity and increased cost per rep. Organizations with a formal enablement strategy that includes structured practice can reduce onboarding time by 40 to 50%. At enterprise rep costs, that compression translates into meaningful recovered revenue capacity per cohort.
AI roleplay built from real call recordings lets new hires practice against scenarios that reflect actual customer conversations from day one. Instead of reading a playbook and shadowing calls for weeks, reps actively practice discovery, objection handling, and value articulation against AI personas that behave like the company's actual buyers.
The ramp advantage is not just speed. It is consistency. Every new rep practices against the same quality of scenarios, receives feedback on the same dimensions, and gets certified against the same standards. That consistency is difficult to achieve with manager-led onboarding alone, especially in distributed or global teams. When a member service representative in a branch that opened six months ago needs to develop financial advisory conversations, they cannot wait for a regional manager's next visit. A practice environment that is always available, always consistent, and always tied to the organization's actual service standards changes what onboarding can accomplish for a geographically dispersed team. For global teams, pronunciation and vocabulary coaching built into the platform keeps language clear, consistent, and on-brand across regions, something no static onboarding module can replicate.
Enhancing Team Performance
For established teams, the challenge shifts. The reps know how to sell. The question is whether the team's collective skills are keeping pace with a shifting market, new competitive pressure, or an updated product line.
A team that consistently runs practice scenarios against updated competitive positioning, that has their live call scores tracked against the same rubric week over week, and that receives targeted micro-practice based on actual performance gaps builds skills incrementally rather than in periodic training bursts that fade within days.
Research from the Journal of Experimental Psychology and cognitive science consistently validates that spaced, targeted practice produces stronger long-term retention than massed training. When coaching is continuous and connected to real deal performance, reps do not just absorb feedback. They practice the specific skill, measure themselves against the same standard on real calls, and adjust based on what they learned in the field. That cycle of practice, performance, and refinement is what separates teams that improve steadily from teams that plateau after each training event.
--
If your team is still running practice and performance review as separate activities, that gap will show up in your pipeline numbers before it shows up in your coaching dashboard. For teams at Level 2 or Level 3 on the maturity model, the specific next move is to find one skill where you can see both practice and live performance scores in the same view, and build from there. For teams already generating high call volume but experiencing stagnating close rates, the priority is connecting existing call analysis to structured re-practice rather than adding another recording tool. Outdoo is built around that closed-loop model, and teams using it across onboarding,renewal calls, and competitive prep tend to report broader skill development than those stitching point solutions together
The insight worth sitting with: it is not the volume of practice that predicts performance improvement. It is whether the practice is directly informed by what the rep did on their last real call.
Frequently Asked Questions
.svg)
Most tools address either practice or performance review, but not in a connected way. Without a feedback loop that ties live call data back into structured re-practice, reps receive insights they have no immediate mechanism to act on, and those insights fade before the next real opportunity arises.
They can, but only if the roleplay system is built from your actual call recordings, playbooks, and product documentation rather than generic sales templates. When AI personas are trained on your buyers' specific language and objection patterns, skill transfer to live calls happens faster and more reliably than with off-the-shelf scenarios.
Track skill-specific scores from roleplay sessions alongside the same scoring dimensions applied to live calls, then look for correlation with pipeline stage conversion rates over 60 to 90 days. Activity metrics like sessions completed or hours logged tell you about participation, not improvement.
Call recording tools identify what happened on a call after the fact. A closed-loop platform takes that analysis and automatically generates targeted practice scenarios based on the specific gaps identified, then scores the rep's next real call against the same criteria to measure whether the practice transferred.
Look for platforms that connect roleplay scoring to live call performance within the same system, not through manual exports or separate integrations. Outdoo, for example, applies the same scoring rubric across both practice and real calls, which is what allows managers to see whether skills transferred rather than guessing. Also verify that the platform supports custom personas built from your own call recordings and playbooks, and that it offers process compliance scoring if your team operates in a regulated environment.



.avif)


